
74% of FDA drug application rejections cite manufacturing and quality issues. Not safety. Not efficacy. Operations. We built Tether Analytics because we lived this problem firsthand and the tools that existed weren't solving it.
The problem we kept running into
Our team has spent a lot of time inside biotech companies. Different companies, different modalities, different stages. And we kept running into the same problem. It was never a lack of data. Every company had more data than they knew what to do with. Batch records, analytical results, process parameters, DOE outputs, stability data. All of it existed somewhere. The problem was "somewhere." That usually meant a shared drive full of Excel files that hadn't been reorganized in two years, a folder of PDFs with inconsistent naming conventions, and critical process knowledge that lived in the heads of whoever happened to be in the room when a decision got made. Several of us have been the person who spent a weekend building a tracking spreadsheet because there was no other way to answer a basic question about process performance. You build it, it works, people start relying on it. Then someone changes the folder structure, or a new team member doesn't know it exists, or the person who built it moves on. And you're starting over. We got tired of starting over. When we stepped back and looked at the broader picture, the numbers made the problem feel even more urgent. In July 2025, the FDA publicly released over 200 Complete Response Letters issued between 2020 and 2024. A CRL is the agency's way of saying your drug application isn't approved yet. This was the first time the industry could see, in detail, exactly why applications were getting rejected. Pharma Manufacturing went through all 202 letters and found that 150 of them, 74%, involved quality or manufacturing issues. Not safety concerns. Not questions about whether the drug works. Manufacturing processes, facility inspections, CMC deficiencies. That number is hard to sit with. Companies pour years and hundreds of millions of dollars into developing a therapy. The science works. The clinical data is there. And then three quarters of them get tripped up by operational problems on the manufacturing side.
This isn't a last-minute problem
The thing that stood out to us when we dug into those CRLs is that these failures almost never come from a single mistake at the end. They build up over time. Analytical methods that were fine for early research but fall apart when regulators evaluate them at commercial scale. Gaps in how a process was documented as it moved between sites. Stability data that's incomplete because nobody centralized the tracking. Process controls that were understood informally but never formalized in a way that holds up to scrutiny. We've watched this happen. Not from the outside, but from inside the labs and manufacturing floors where people are doing the actual work. The scientists and engineers we've worked alongside weren't making bad decisions. They were making the best decisions they could with the tools they had. The tools just weren't good enough. That's the part that got under our skin. Most software in this space is built around organizing data. Upload your files, search your records, tag your documents. And that's real value, we're not dismissing it. But it stops short of the question that actually matters day to day: what is my process doing and what should I expect next time? That's what a process scientist needs when they're managing a cell therapy expansion and trying to figure out why viability dropped after the last harvest. That's what an engineer needs when they're troubleshooting a deviation and want to know if this has happened before and what the root cause was. That's what a CMC lead needs when they're building a regulatory submission and trying to demonstrate that they genuinely understand their process, not just that they can follow a protocol. You can have perfectly organized files and still not be able to answer those questions. We know because we've been there.
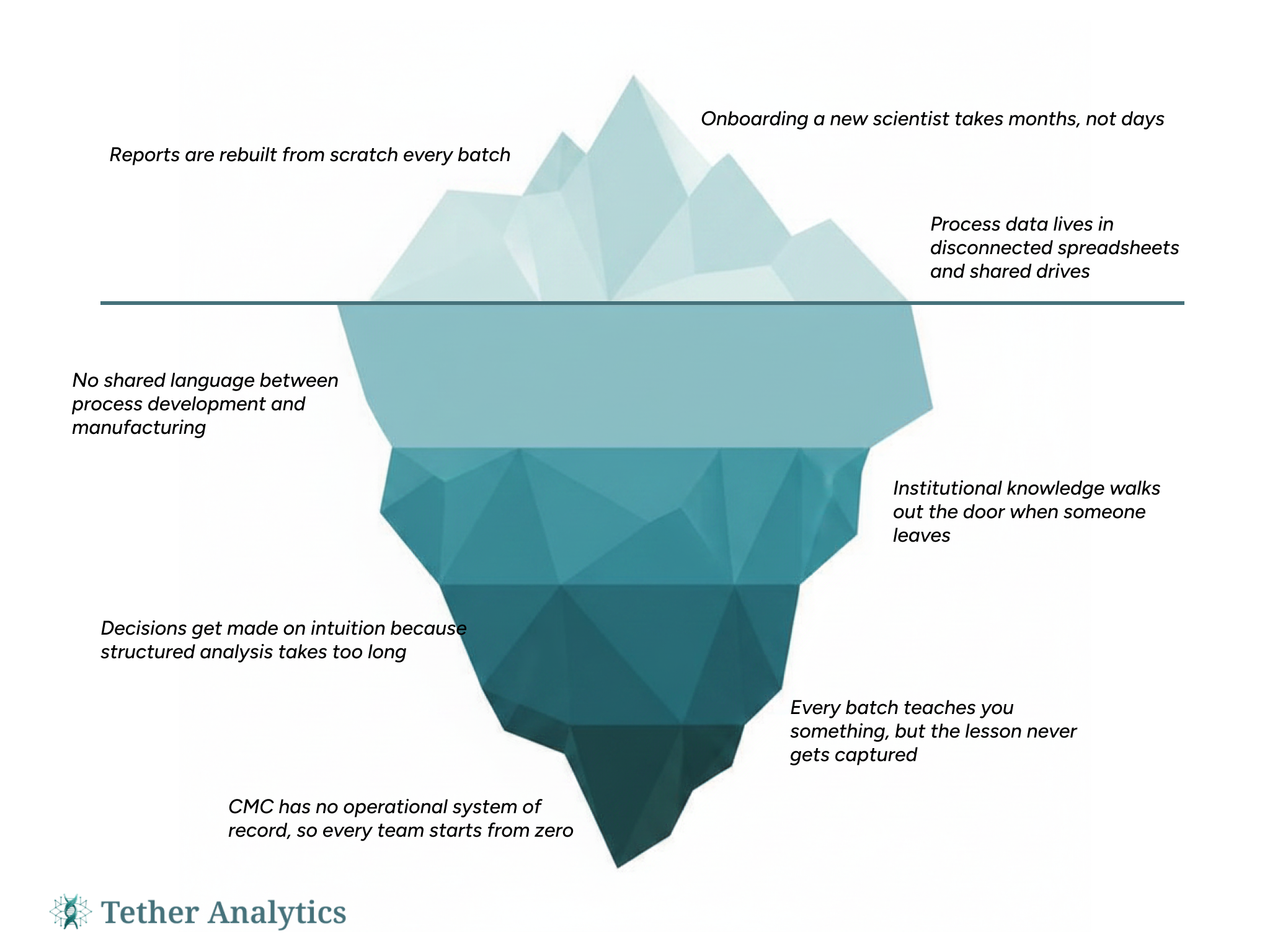
What we're building
Tether Analytics gives process development and manufacturing teams a unified view of their process. You bring in your process descriptions, batch data, and SOPs. Tether structures it, connects it, and builds models calibrated from your actual data. Not from generic templates or textbook equations. From what your process is actually doing. The AI layer isn't there to replace anyone's judgment. It's there to surface things that would take days or weeks to find manually. To quantify relationships between process parameters that teams have been tracking by feel. To get sharper with every new batch because each data point refines the model. We built this for process development scientists, manufacturing engineers, and CMC leads. The people who are responsible for getting programs to IND and beyond, and who know firsthand what it costs when a preventable issue becomes a CRL. We're still early. There's a lot of work ahead. But we started Tether because we needed something like it and it didn't exist. We'd been building workarounds inside companies for years, and every workaround eventually broke. At some point you stop patching the problem and start building the thing that should have been there all along. 74% of FDA application rejections involve manufacturing and quality issues. That's not a number that has to stay where it is. We're building Tether for the teams that are ready to close that gap.